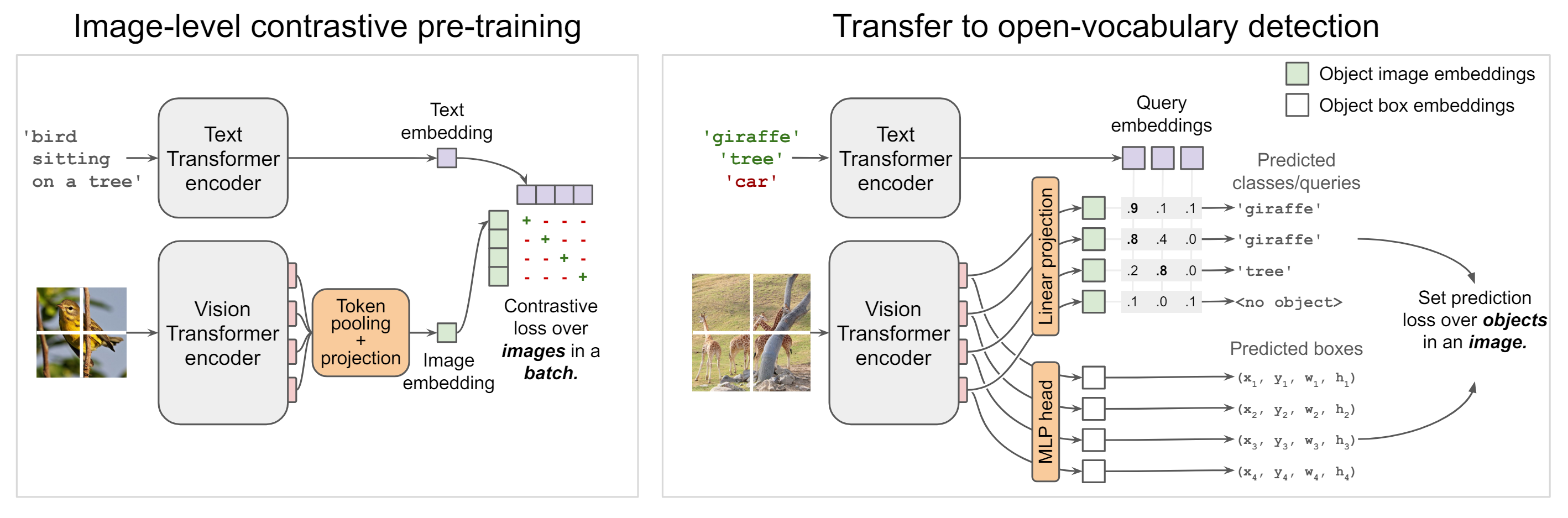
OWL-ViT
This post is based on Simple Open-Vocabulary Object Detection with Vision Transformers written by google research in 2022
Here is main contribution of this paper
- Simple and strong Vision-Language Model for Object detection
- Thanks to the Contrastive learning and pre-training for large-scale image-text data, it can be available to open-vocabulary object detraction
How to train